 Ali Ferda Arikan
Ali Ferda Arikan
Do you really want to use a managed language?
Recently I have attended a very inspiring talk by Martin Thompson at QCon London titled High performance Managed Languages. The title itself was very interesting in the sense that managed languages and high performance were not two words I would use together in the same sentence. The talk was very inspiring and I would suggest you to look at Martin Thompson’s presentation for a good look at performance and some tips on how to get high performance. Personally I always maintained the idea of “the closer you get to the hardware, more faster your code runs”. Knowing how hardware functions, helps developing high performing code. This way you can maintain the harmony between your code and the hardware. I think it is time for another car analogy. A super-car may be very powerful but if it is not driven by the right driver who can actually enable that high performance, the car will never perform well. We can think that the software is the driver and car is the hardware. A driver driving a car for the first time or driving a car that she is trained for will deliver different kind of performance. Having the managed runtime lying between your code and the CPU seems to create an isolation layer between the code you develop and the hardware. It almost gives the impression of having another driver in between the car and its driver. This often results in the fake sense of security that “someone” will deal with the hardware or the driving.
Developing in a native language will require different set of skills that you may not notice that you need them when developing in a managed language. I deliberately say ‘you may not notice’ as most of the time your code will run ‘just fine’ even though you don’t have a basic understanding of the fundamental concepts. In a native language you don’t have much chance to survive without a good understanding of the fundamentals. This almost creates an entry barrier for native languages and sometimes a distraction for developers. The performance comes with a high cost. However people who are ready to pay this high cost get equipped with very valuable information.
When we compare managed and native languages we tend to always talk about the productivity gains of the managed languages. This is in fact a big benefit but this tends to sometimes overshadow other advantages. Often, when programming in a managed language, developers don’t tend to focus on performance. This is not perceived as the main offering of a managed language. Whenever I ask a C# developer the reasons behind choosing C# as their main language, they often mention many other benefits. I didn’t see anyone yet adding performance in their list. This almost turns into a self-fulfilling prophecy. If the developers start programming by already giving up on performance they tend to, deliberately or not, degrade the performance even further. We all know that IO is expensive however this gets forgotten when it comes to designing a new piece of software. Most of the time ‘It ain’t broke don’t fix it applies’ for some. Some, brand certain fundamental trivial stuff as early optimisation. However inaction is the cause of the problems here. Harmless few milliseconds all contribute up to a snowball.
Recently I read a very interesting article 68 things happen before you execute your code. Reading this article raised more questions in my mind about the performance of the language I am developing with. If all of those are really happening before my code is executed getting rid of them should be a massive gain, one can conclude. However these also provide massive amount of debugging/profiling information.
The runtimes have their advantages such as the profile guided optimisations and bets. Managed runtimes can take bets on how to execute a particular piece of code, on how to optimize or when to run code blocks. The nice thing is that those bets can be revoked by the runtime if they are proven to be wrong. This is a massive benefit over native languages where all the optimizations happen at compile time and therefore static. Having a runtime between hardware and the code gives another layer to do the optimizations. In theory it should be possible to introduce better optimisations or support for newer instructions with a newer version of the runtime. (actually that is already happening here).
//A trivial performance trap
public static void DoWork(string name, DateTime transactionDate, string scenario)
{
var items = GetItems(transactionDate);
foreach (var item in items)
{
var otherItem = GetOtherItem(name, scenario);
DoMoreWork(item, otherItem);
}
}
Conclusion
I am sorry to tell this directly but it is not the language, most of the time it is you. If you want your code to perform well then write it in a way that it actually performs well. Knowing how the code is executed, memory is accesed, identifying the bottlenecks and creating the right design for the problem will help you get a much better performance from your code. I still like C++ and also C# and I don’t see them as alternatives to each other. Picking a language is a decision based on many parameters like, developers, available skills, requirements, platform that the code will run, architecture and so on. However whatever language is picked certain fundamental principles do not change and still valid and affects the performance of the application.
Fun Part
In Martin Thompson’s presentation I was really amazed to see the results about the performance of different memory access patterns. Average ns/op varies between 1 and 90 depending on the access pattern.
How does, for example, cache lines matter and how does it affect the performance of the application. I wanted to give it a go to see myself. Let’s assume we have a very large array,int[64*1024*1024]. Now we can look at the performance of two scenarios.
- Case 1: Iterate over each element and make an operation on each 67.108.864 element.
- Case 2: Iterate over the same array by skipping 16 elements to make the same operation for 4.194.304 times.
Now the question is how long each loop take in milliseconds and how much time is spent per operation. If you look at below results you may notice that there is only few millisecond difference between the two loops. Now please look at below results and compare the time taken for both loops. Is it something you were expecting to see? Now look at nanoseconds taken for each operation, and notice which one is faster.
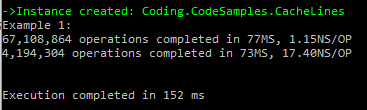
I also got strange results like below where longer loop completed in shorter time. I guess this is due to both loops have same memory access cost and the variability comes from the performance of the operations.
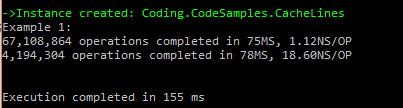
I used a modified version of this to produce the results. One of the modifications I made was to make sure that the second loop skips a whole cache line.
References:
- https://mariantines.com/2015/08/24/simd-support-in-net-framework/
- http://stackoverflow.com/questions/6396240/performance-when-generating-cpu-cache-misses
- http://mattwarren.org/2017/02/07/The-68-things-the-CLR-does-before-executing-a-single-line-of-your-code/
- https://qconlondon.com/london-2017/presentation/high-performance-managed-languages
- https://martinfowler.com/articles/lmax.html
- https://mechanical-sympathy.blogspot.co.uk/