Introduction
The philosophies underpinning our infrastructure deployment strategy are threefold:
- Infrastructure is at its best, most known, and most stable state right after it is freshly deployed.
- Long-running containers and servers tend to break.
- Fault tolerance cannot be bolted-on as an afterthought. It has to be designed-in from the beginning.
We have built these ideas directly into our systems. We run containers, we run in the cloud.
Failure is inevitable, and resiliency is not just desirable, but essential.
In fact, failing is okay. Containers and servers going down is fine, because we’ll just spin up another one. We have enough redundancy built into our system to tolerate it.
Our system is more reliable because it deals with failure all the time – daily, hourly – and it recovers seamlessly. If a real disaster happens, our system will recover because it already does it all the time.
What is the ‘Reaper’?
Much like Netflix’s idea of a chaos monkey, the Reaper is a process whereby every hour, we blow away an entire container host in Rancher, along with all its containers. The host is simply deleted, as if it had gone offline.
Our system is designed to tolerate this failure with no downtime for the users, and to automatically recover.
The Reaper is constructive destruction.
Okay, but how does it work?
The ‘Reaper’ takes the form of Azure Powershell deploy scripts that are checked into Github, and built on a cron schedule by Jenkins. Usually they run hourly, like so:
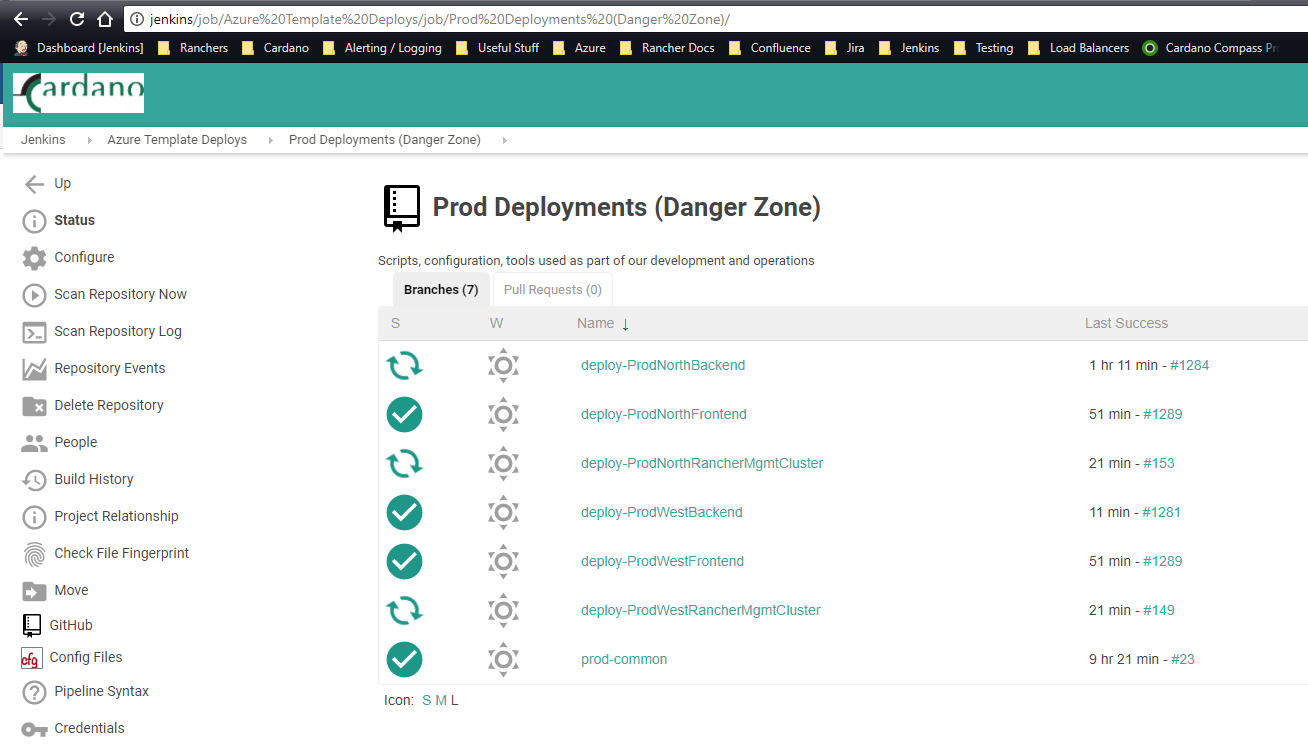
The Powershell scripts have the following steps:
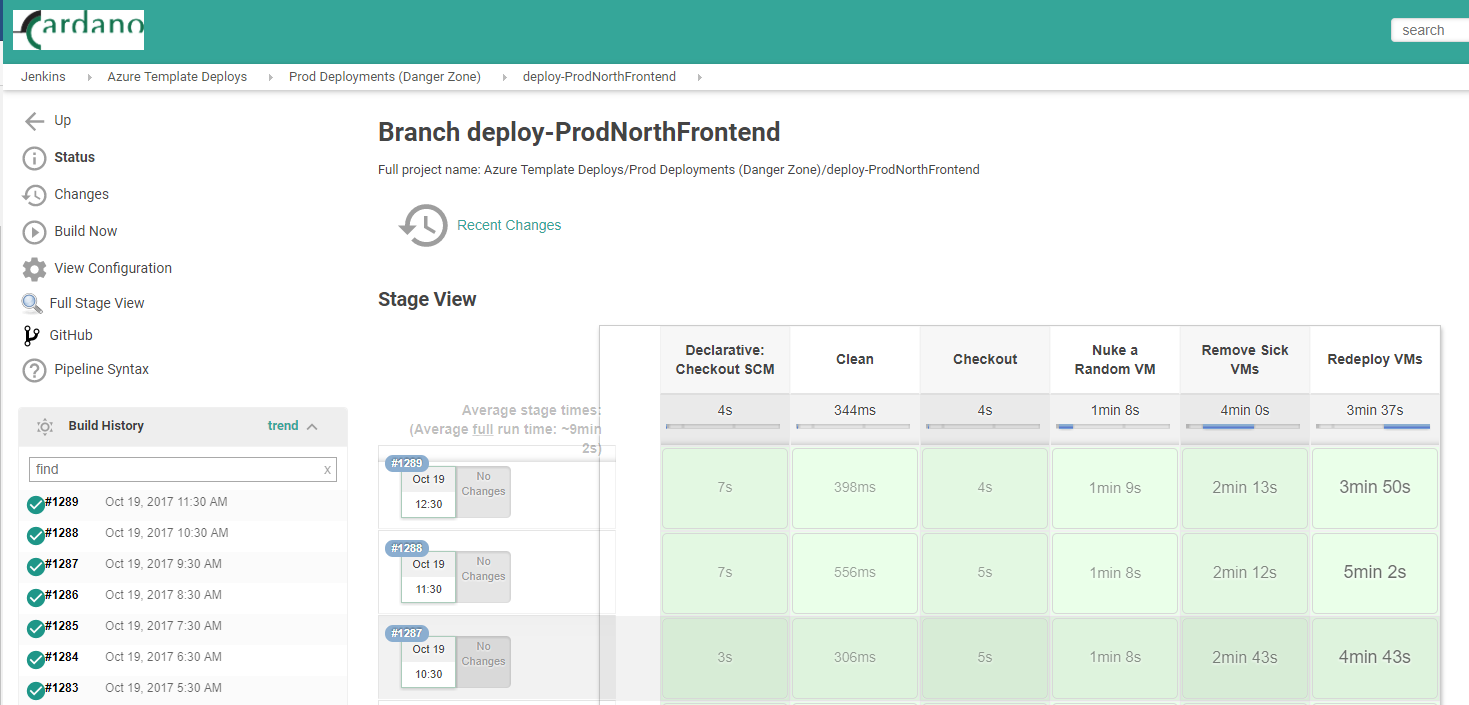
The logical process flow is as follows:
- Are there alerts firing for this environment? If so, don't do anything destructive. Skip to step 4.
- If no alerts are firing, and all stacks in the environment are healthy, nuke a VM instance. Just delete it.
- Check for sick, removed, or 'zombie' hosts in Rancher (via the REST API and Azure Powershell cmdlets). Clean them up if found.
- Redeploy the Azure Template to heal the environment.
- Azure will automatically trigger a rebuild of the missing VM via its VM Scale Set scaling algorithm.
- A new host comes online to replace the deleted one, and Rancher re-balances the containers. There is no downtime for the user.
What are the benefits of this?
This means our environment is always moving, always refreshing, always self-healing.
We are always exercising our failure recovery. If a container goes down, if an entire VM goes down, and (to an extent) if an entire region goes down, we can recover, in most cases automatically.
It also encourages developers to build fault-tolerant apps, since they will need to survive this creative destruction in order to operate in our environment. If an app isn’t tolerant of failure it won’t work at all.
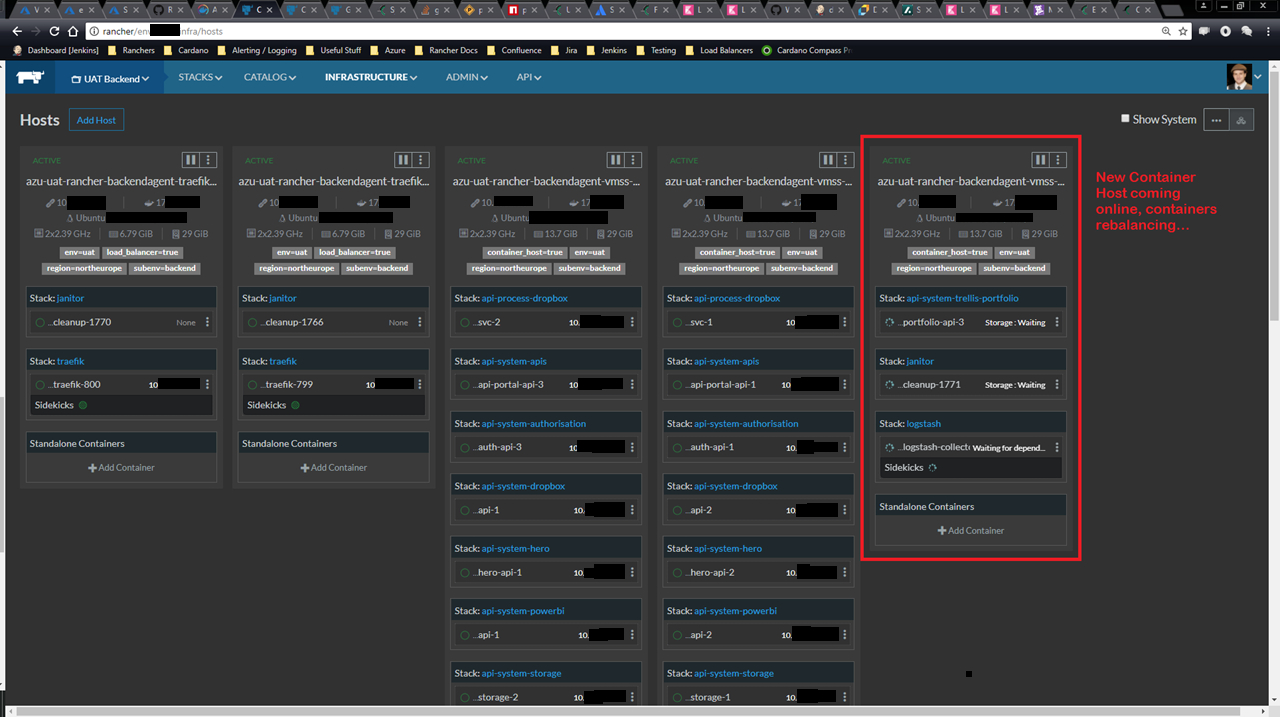
What does Rancher look like when a host is recycling?
It looks pretty red and angry, in fact. But you’ll notice the stats all say “Degraded”, not “Stopped”. They are still working, just at a reduced container count due to the missing host:
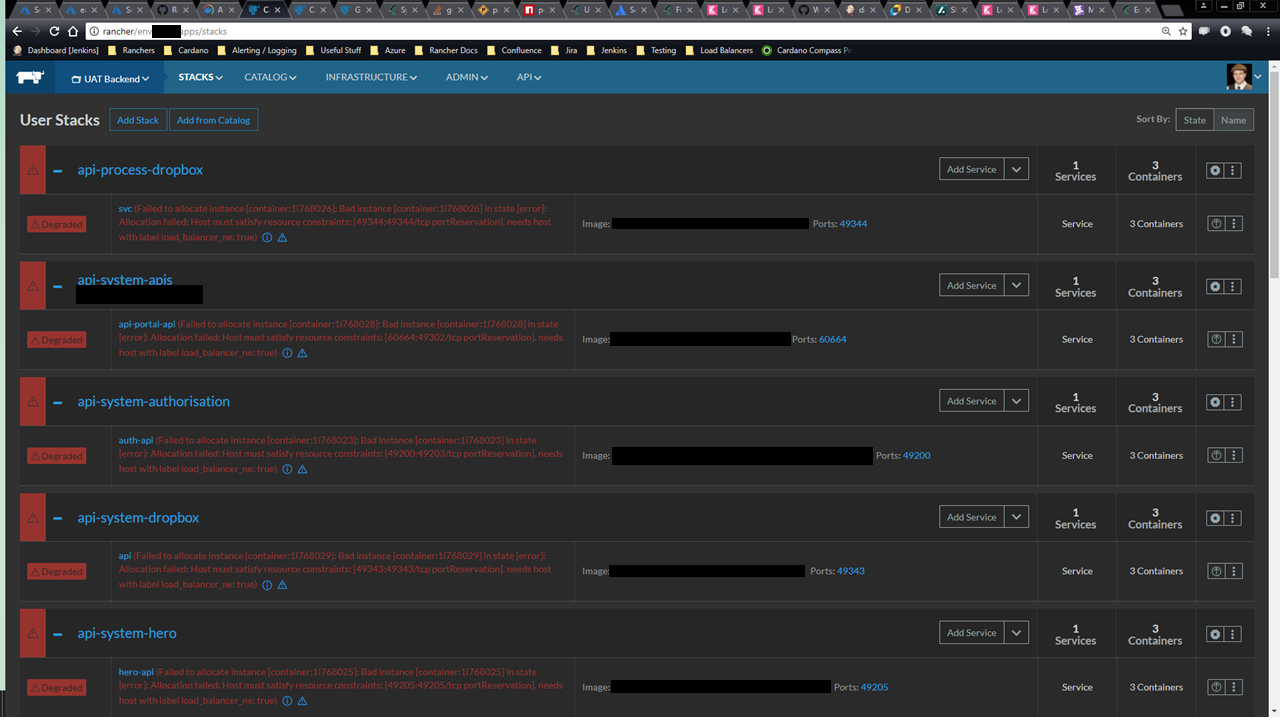
So if you see all the stacks in a degraded state, don’t worry. Compass is still running fine:
And Rancher will gradually rebalance the containers when the host comes back (usually within 5 minutes):
Conclusion
- Write your apps using a queue model (like RabbitMQ) for operations that must succeed
- Write your apps to be fault tolerant
- Write your apps to be stateless, or to keep state in Redis
- Write retry logic into your calls, don't always assume they will succeed
- Don't fear the Reaper